

In this tutorial, we will learn how to build a web scraper with Go and Colly. We will also learn how to save our scraped data into a JSON file. Sometimes some things just don’t have an API. In those kinds of cases, you can always just write a little web scraper to help you get the data you need.
We’re going to be working with Go and the Colly package. The Colly package will allow us to crawl, scrape and traverse the DOM.
Prerequisites
To follow along, you will need to have Go installed.
Setting up project directory
Let’s get started. First, change into the directory where our projects are stored. In my case this would be the “Sites” folder, it may be different for you. Here we will create our project folder called rhino-scraper
| |
In our rhino-scraper project folder, we’ll create our main.go file. This will be the entry point of our app.
| |
Initialising go modules
We will be using go modulesto handle dependencies in our project.
Running the following command will create a go.mod file.
| |
We’re going to be using the colly package to build our webscraper, so let’s install that now by running:
| |
You will notice that running the above command created a go.sum file. This file holds a list of the checksum and versions for our direct and indirect dependencies. It is used to validate the checksum of each dependency to confirm that none of them have been modified.
In the main.go file we created earlier, let’s set up a basic package main and func main().
| |
Analysing the target page structure
For this tutorial we will be scraping some rhino facts from FactRetriever.com.
Below is a screenshot taken from the target page. We can see that each fact has a simple structure consisting of an id and a description.
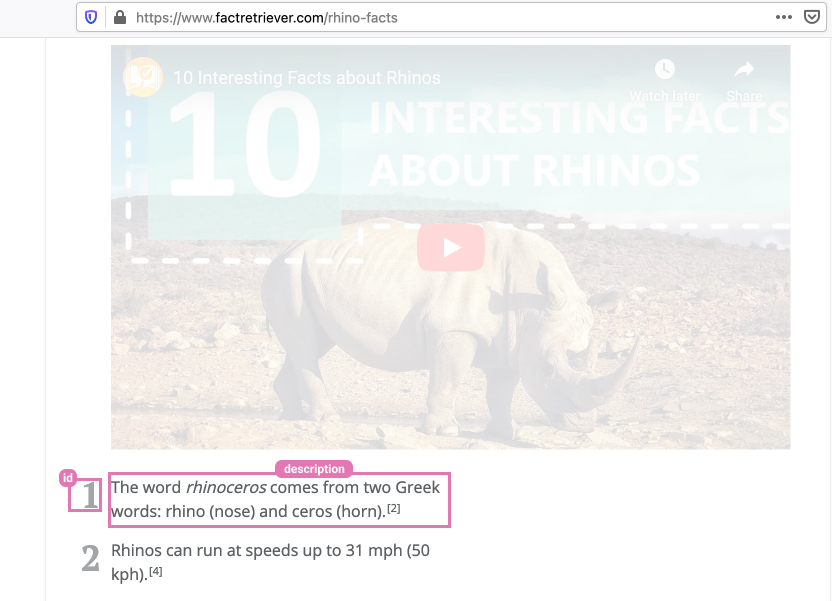
Creating the fact struct
In our main.go file, we can write a Fact struct type to represent the structure of a rhino fact. A fact will have:
- an ID that will be of type
int, and - a description that will be of type
string.
The Fact struct type, the ID field and the Description field are all capitalised because we want them to be available outside of package main.
| |
Inside of func main, we will create an empty slice to hold our facts. We will initialise it with length zero and append to it as we go. This slice will only be able to hold Facts.
| |
Using the Colly package
We will be importing a package called colly to provide us with the methods and functionality we’ll need to build our web scraper.
| |
Using the colly package, let’s create a new collector and set it’s allowed domains to be factretriever.com
| |
HTML structure of a list of facts
If we inspect the HTML structure, we will see that the facts are list items inside an unordered list that has the class of factsList. Each fact list item has been assigned an id. We will use this id later.
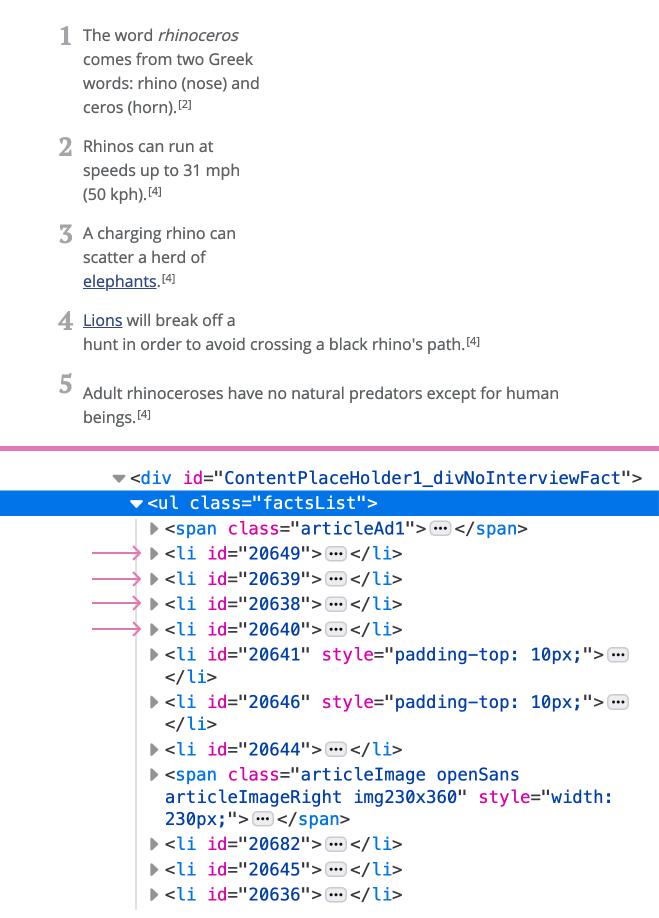
Now that we know what the HTML structure is like, we can write some code to traverse the DOM. The colly package makes use of a library called goQuery to interact with the DOM. goQuery is like jQuery, but for Golang.
Below is the code so far. We will go over the new lines, step-by-step
| |
- Line 3-6
- We import the
fmt,logandstrconvpackages
- We import the
- Line 23
- We are using the
OnHTMLmethod. It takes two arguments. The first argument is a target selector and the second argument is a callback function that is called everytime a target selector is encountered
- We are using the
- Line 24
- In the body of the
OnHTML, we create a variable to store the ID of each element that is iterated over - The ID is currently of type
string, so we usestrconv.Atoito convert it to typeint
- In the body of the
- Line 25-27
- The
strconv.Atoimethod returns an error as it’s second return value, so do some basic error handling
- The
- Line 29
- We create a variable called
factDescto store thedescriptiontext of each fact. Based on the Fact struct type we established earlier, we are expecting the fact description to be of typestring.
- We create a variable called
- Line 31-34
- Here, we create a new Fact struct for every list item we iterate over
- Line 36
- Then we append the Fact struct to the allFacts slice
Begin crawling and scraping
We want to have some visual feedback to let us know that our scraper is actually visiting the page. Let’s do that now.
| |
- Line 39-41
- We use
fmt.Printlnto output aVistingmessage whenever we request a URL
- We use
- Line 43
- We use the
Visit()method to give our programme a starting point
- We use the
If we run our program in the terminal now, by using the command
| |
It will tell us that our collector visited the rhino facts page on Fact retriever.com
Saving our data to JSON
We may want to use our scraped data in another place. So let’s save it to a JSON file.
| |
- Line 5
- We import the
ioutilpackage so we can to write to a file
- We import the
- Line 7
- We import the
ospackage - The OS package provides an interface to operating system functionality
- We import the
- Line 49
- Let’s create a function called writeJSON that takes in one parameter of the type slice of fact
- Line 50
- Inside the function body, let’s use
MarshalIndentto marshal the data we pass in - The
MarshalIndentmethod returns the JSON encoding of data and also returns an error
- Inside the function body, let’s use
- Line 51-54
- Some error handling. If we get an error here, we will just print a log message saying we were unable to create a JSON file
- Line 56
- We can then use the
WriteFilemethod it provides us to write our JSON-encoded data to a file called"rhinofacts.json" - This file does not exist yet, so the
WriteFilemethod will create it with the permissions code of 0644.
- We can then use the
Our WriteJSON function is ready to use. We can call it on Line 8 and pass allFacts to it.
Now if we go back to the terminal and run the command go run main.go, all our scraped rhino facts will be saved in a JSON file called "rhinofacts.json".
Conclusion
In this tutorial, you learnt how to build a web scraper with Go and the Colly package. If you enjoyed this article and you’d like more, consider following Div Rhino on YouTube.
Congratulations, you did great. Keep learning and keep coding!